Spark 学习记录
我为什么要写这个学习笔记呢?
一个原因是我觉得边学边整理笔记能更好的学习和理解
第二个原因就是 Apache 的项目文档实在是太烂了, 以至于我觉得有必要写一篇文章来总结一下 Spark 的核心概念和执行流程了, 这样也能帮助其他人更好地理解 Spark 的设计和实现了
Spark 对数据的建模
要理解 Spark 的执行流程, 我觉得先得理解函数式编程中的一些概念, map, reduce, collect …
其中这些操作还要分成两个类别:
- Transformation: 以 map、filter、groupByKey 等为代表, 这些操作都是惰性的, 不会立即执行
- map: 对集合中的每个元素应用一个函数, 生成一个新的集合
- [1, 2, 3].map(x => x * 2) => [2, 4, 6]
- reduce: 将集合中的元素两两组合, 直到剩下一个结果
- [1, 2, 3].reduce((x, y) => x + y) => 6
- 上面的操作实际上都应该是惰性的, 他们只是定义了一个操作链, 但并没有真正执行, 只有当我们调用了 Action 的时候, 这个操作链才会被触发执行, 我在后面给出数据只是为了说明这个概念
- Action: 以 collect、count、saveAsTextFile 等为代表, 他们表示把最终我们 Transform 的数据以某种方式收集起来, 这些操作会触发实际的计算, 他们是这条操作链的终点, 一旦调用了这些 Action, 上面所说的 Transformation 链就会被触发执行, 计算结果会被返回或者写出到外部存储
- collect: 将分布式数据集合中的所有元素收集到 Driver 程序中
- count: 计算分布式数据集合中的元素数量
其中 map, reduce 等各种操作都不会改变原来的数据, 而是生成一个新的数据集合, 这就是函数式编程的核心思想: 不可变数据和纯函数
于是, 对数据的处理就可以抽象成各种 functional transformations, 以及最终的 actions
这看起来很好, 但是如果数据量很大, 那么直接对一个超级大的数组或者 Set 来执行这些操作就不现实了, 第一是因为内存不够, 第二是因为单机的计算能力有限, 这时候我们就需要分布式计算了, Hadoop MapReduce 就是基于这个思想设计的, 但是它的编程模型比较底层, 不够灵活, 而且性能也不太好, 于是 Spark 就在这个基础上做了很多改进, 使得分布式计算变得更高效, 更易用, 具体修改了什么就不说了
要实现大数据这样的统计计算, 需要进行分布式存储和分布式计算, 因此对这些数据进行进一步的抽象建模是很有必要的
Spark 对数据的建模
Spark 有三层数据抽象,从低到高:
- RDD(Resilient Distributed Dataset): 最底层的抽象,核心概念:
- 数据被切分成多个 Partition(分区),分布在集群的不同节点上, 逻辑上类似于把数组切成好几份, 切分方法可以有 Hash, 或者直接有几个分隔的 value 或者直接划开
- RDD 是不可变的,所有的 Transformation 都会生成一个新的 RDD
- 惰性求值: Transformation 只记录血缘(也就是一个新的RDD是由哪个旧的RDD经过什么操作生成的),只有 Action 才会触发计算, 这个如果你接触过 Haskell 也是差不多的, 也就是说对一个 RDD 进行 map, filter, 他只会记录一个计算的链条
- 容错性: 由于 RDD 记录了血缘关系,如果某个 Partition 的数据丢失了,Spark 可以根据血缘关系重新计算这个 Partition 的数据 RDD 的核心元数据:
RDD
├── partitions() # Partition 列表
├── dependencies() # 父 RDD 的依赖关系(血缘)
├── compute(partition) # 如何计算这个 Partition
├── partitioner # 可选,数据按什么规则分区(Hash/Range)
└── ... # 以及各种其他的属性, 如是否缓存、是否持久化等- DataFrame / Dataset: RDD本质只是一个大大的数组, 对于里面每个元素并没有什么 Schema 来描述它, DataFrame / Dataset 建在 RDD 之上, 带有 Schema(列名 + 类型), 类似关系型数据库的表
但是 DataFrame / Dataset 就更像一个真正的表了, 类似 Vector<Map<String, Object>> 这样的结构, 每一个元素都是一个 Row, 里面有列名和对应的值, 这样就可以更方便地进行 SQL 查询了
在 Spark 中是这样表示的:
- DataFrame = Dataset[Row], 其中 Row 是一个特殊的类型, 代表一行数据, 里面有列名和对应的值(在这里为了简单理解, 可以把 Row 看成一个
Map<String, Object>) - Dataset[T] 是一个类型安全的分布式数据集合, 其中 T 是一个普通的 Java/Scala 对象, 代表一行数据, 里面有字段和对应的值, 这样就可以更方便地进行类型安全的操作了
- 但是 RDD 也不是完全只是一个[Value] 的大数组, 但他是[(K, V)]这样的元组的数据时候, 也有一些类似 SQL 的操作
- 物理存储: Partition 无论哪层抽象,数据最终都以 Partition 为单位存在内存或磁盘里。Partition 是并行度的基本单位,也是 Task 处理的基本单位
其中 RDD 是怎么进行分区的呢? 有三种方法
- 水平分区: 按照record的索引进行划分, 常常是最开始的 RDD 的分区方式 例如,我们经常使用的sparkContext.parallelize(list(1,2,3,4,5,6,7,8,9),3),就是按照元素的下标划分,(1,2,3)为一组,(4,5,6)为一组,(7,8,9)为一组。这种划分方式经常用于输入数据的划分,如使用Spark处理大数据时,我们先将输入数据上传到HDFS上,HDFS自动对数据进行水平划分,也就是按照128MB为单位将输入数据划分为很多个小数据块(block),之后每个Spark task可以只处理一个数据块
- Hash 分区: 使用record的Hash值来对数据进行划分, 该划分方法经常被用于数据Shuffle阶段
- Range 分区: 该划分方法一般适用于排序任务,核心思想是按照元素的大小关系将其划分到不同分区,每个分区表示一个数据区域 例如,我们想对一个数组进行排序,数组里每个数字是[0,100]中的随机数,Range划分首先将上下界[0,100]划分为若干份(如10份),然后将数组中的每个数字分发到相应的分区,如将18分发到(10,20]的分区,最后对每个分区进行排序,这个排序过程可以并行执行,排序完成后是全局有序的结果。Range划分需要提前划分好数据区域,因此需要统计RDD中数据的最大值和最小值。为了简化这个统计过程,Range划分经常采用抽样方法来估算数据区域边界
分布式的计算模型
我们在存储的时候, 已经把数据拆分成了一个个的 Partition, 这些 Partition 分布在集群的不同节点上, 计算的时候就可以并行地对这些 Partition 进行处理了, 最后在把计算的结果聚合起来, 这就是分布式计算的核心思想
但是,分布式计算并不是简单地把数据拆分开来,然后并行执行就完了,还需要解决以下几个问题
- 如何描述计算任务:我们需要一种方式来描述对数据的操作,这种描述需要足够抽象,能够适用于各种不同的计算场景
- 如何调度计算任务:我们需要一种方式来调度这些计算任务,让它们在集群的不同节点上并行执行
- 如何处理依赖关系: 我们把数据分区之后, 不同的分区可能会有依赖关系, 比如说一个分区的数据需要另一个分区的数据作为输入(比如 groupByKey), 这时候我们就需要处理这些依赖关系, 确保计算的正确性
Spark 对这三个问题的解答就是:DAG + Stage + Task
DAG(Directed Acyclic Graph)
当你写下一串 Transformation 的时候,Spark 并不立即执行,而是把这些操作记录成一张有向无环图(DAG),图中每个节点是一个 RDD,每条边是一个 Transformation
textFile → filter → map → reduceByKey → filter → collect
RDD0 RDD1 RDD2 RDD3 RDD4 (Action)直到 collect() 这个 Action 被调用,Driver 才拿着这张 DAG 图开始规划执行
Stage: 按照 Shuffle 边界划分
DAG 里的操作并不都是等价的,有两种依赖关系:
- 窄依赖(Narrow Dependency):如果新生成的child RDD中每个分区都依赖parent RDD中的一部分分区
- 宽依赖(Wide Dependency / Shuffle):如果从数据流角度解释,宽依赖表示新生成的child RDD中的分区依赖parent RDD中的每个分区的一部分
典型的窄依赖操作有 map、filter、flatMap 等,典型的宽依赖操作有 groupByKey、reduceByKey、join 等
这里出现了一个新名词:Shuffle, Shuffle 是一道天然的执行屏障:Shuffle 之前的所有数据必须计算完毕并写到磁盘,下一批计算才能去各个节点拉取数据开始执行。
因此 Spark 以宽依赖为切割点,把 DAG 划分成多个 Stage
Stage 又分为两种类型:
- ShuffleMapStage: 中间阶段, 输出写到磁盘供下一个 Stage读取
- ResultStage: 最终阶段, 输出结果返回 Driver 或写到外部存储
简单来说, 我们可以把 Stage 理解为一个连续的操作链, 这个链中不会出现一个宽依赖, 可以在同一个节点上流水线执行, 直到遇到一个宽依赖(Shuffle)或者 Action, 就切一刀, 形成一个 Stage 的边界
觉得很抽象? 没关系, 下面会有一些例子
Task: Stage 内的最小执行单元
每个 Stage 内部,按 Partition 数量拆分成若干个 Task,一个 Partition 对应一个 Task,由 Executor(位于 Worker 节点上的一个进程) 上的一个线程来执行
注意 Task 的个数是由 Stage 最后的 RDD Partition 数目决定的!!!
一些常见的 Transformation 实现
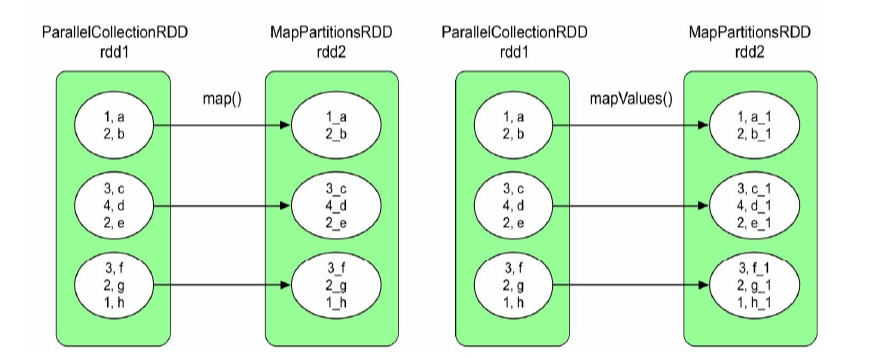
Map/MapValues
FlatMap/FlatMapValues
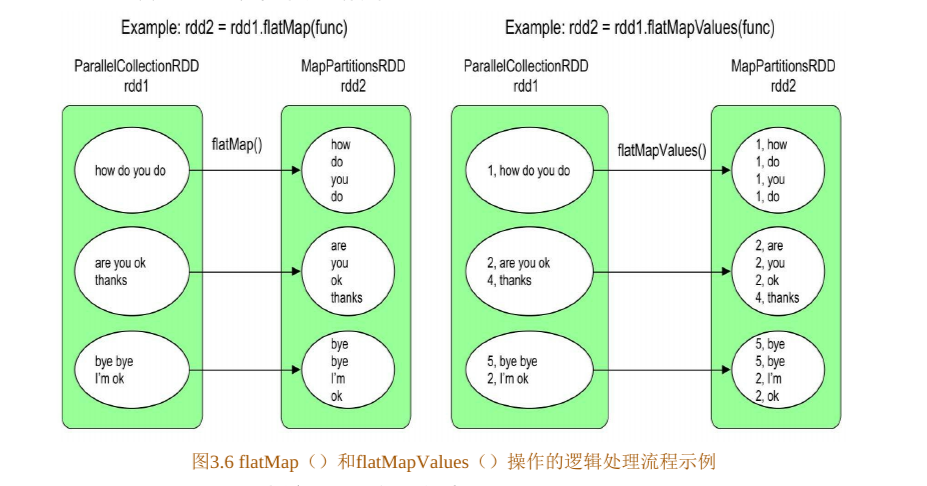 很常规的实现, 子RDD 有几个分区, 就有几个Task, 由于都是一对一的, 直接去父 RDD 的对应分区, 调用 func就好了
很常规的实现, 子RDD 有几个分区, 就有几个Task, 由于都是一对一的, 直接去父 RDD 的对应分区, 调用 func就好了
还有 filter啊, mapPartiton 之类的也差不多, 这里就不多说了
GroupByKey
类似SQL 中的 GroupBy 一样, 需要将 Records 通过 Key聚合起来, 你可能觉得这个肯定是宽依赖, 但是这个可能得看实际情况
GroupByKey 产生的 RDD 分区是通过 Hash分区的, 有什么影响呢?
如果父 RDD 的 Partitioner 和这个 GroupByKey 的 RDD Partitioner 一样! 那么就是窄分区
如下面图片
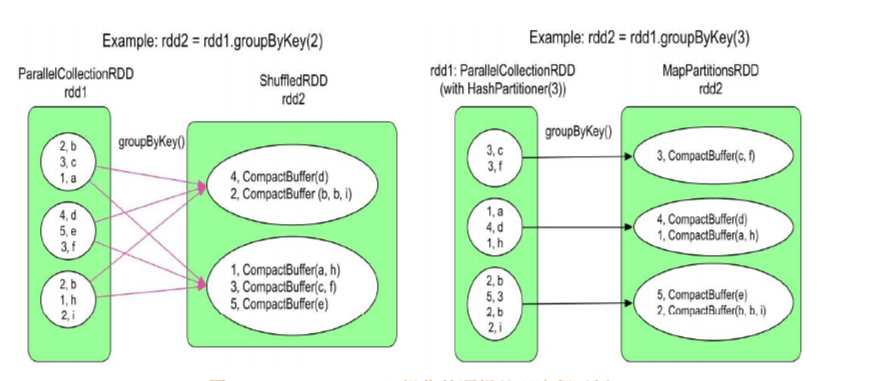
左图的宽依赖
GroupByKey 的实现是先将父 RDD 的每个分区先通过 Hash 小规模聚合起来, 最后每个分区都能得到通过 Hash 的 N 个子分区, 最后把所有的这些字分区聚合起来, 因为一样的 Key 一定会在 Index 相同的子分区的, 所以最后可以得到 N 个聚合的子分区, 聚合方式是如果 Key 相同, 就 Merge
这里就会产生宽依赖了, 因为每个子 RDD 的分区数据来源于父 RDD 的每个 RDD 的一部分 Records
由于产生宽依赖, Spark 会把执行流程分成两个 Stage 了, 左边的 Stage1 有三个 Task, 右边的 Stage2 有两个
Stage1 的 三个 Task最终把这个 RDD1 计算完之后, 他们的 Task 还没有跑完, 还有最后一个步骤: 要把数据交给下一个 Stage, 我们把这个步骤叫 Map side端的Shuffle Write
每个 Task 分别对自己负责的分区进行 Hash 划分, 划分成 2 个分区, 这里记作 p{i}-{n}(或写作 p_i-n), i指的是 Task, n指的是子分区的 index, 将这些数据持久化到磁盘上, Stage1 便是完成了
Stage2 的开始步骤就是先从 Stage1 持久化的这些数据, 进行操作, 我们把这个叫做Reduce side端的Shuffle Read 阶段
Stage2 的每个 Task_i, 直接去拿 p{0-N}-{i}(或写作 p_0-N-i)里的所有数据, 把每个小分区的 Records 都聚合起来, 这里的聚合操作就是如果 Key 相同, 就 merge
右图的窄依赖
如果父 RDD 的 Partitioner 和这个 GroupByKey会产生的 的 子RDD Partitioner 一样, 也就是每个父 RDD 的分区i, 其实只能产生子分区i, 其他的子分区都是空的, 那么直接把这个父RDD的子分区聚合一下, 就能得到子RDD对应的分区了
其他的 reduceByKey 也和这个差不多, 唯一区别的就是, 上面说的 Mapside 聚合操作是空, ReduceSide 的聚合操作是 merge, 这里是调用 func
aggregateByKey 是在 reduceByKey 的基础上, 区分了父 RDD mapSide 的 func 和 子 Rdd reduceSide 的 func
combineByKey 是在 aggregateByKey 的基础上, 又提供了一个 zeroValue 的初始化函数
foldByKey 是在 reduceByKey 的基础上, 又提供了一个 zeroValue 的初始化函数
cogroup()/groupWith 两个 RDD 的 groupByKey 操作, 最后得到的 record 是(K, List[V], List[W])
join 操作
同样类似 SQL, 将两个 RDD的 Records 通过 Key 相同进行聚合
他的计算逻辑是, 先通过 cogroup()/groupWith() 得到一个 (K, List[V], List[W]) 的 RDD, 最后对 List[V], List[W], 进行笛卡尔积
他生成的 RDD 也是 Hash 分区, 和上述的 GroopByKey 一样, 也会因为父 RDD 和 子 RDD的分区, 造成不同的 Stage结果
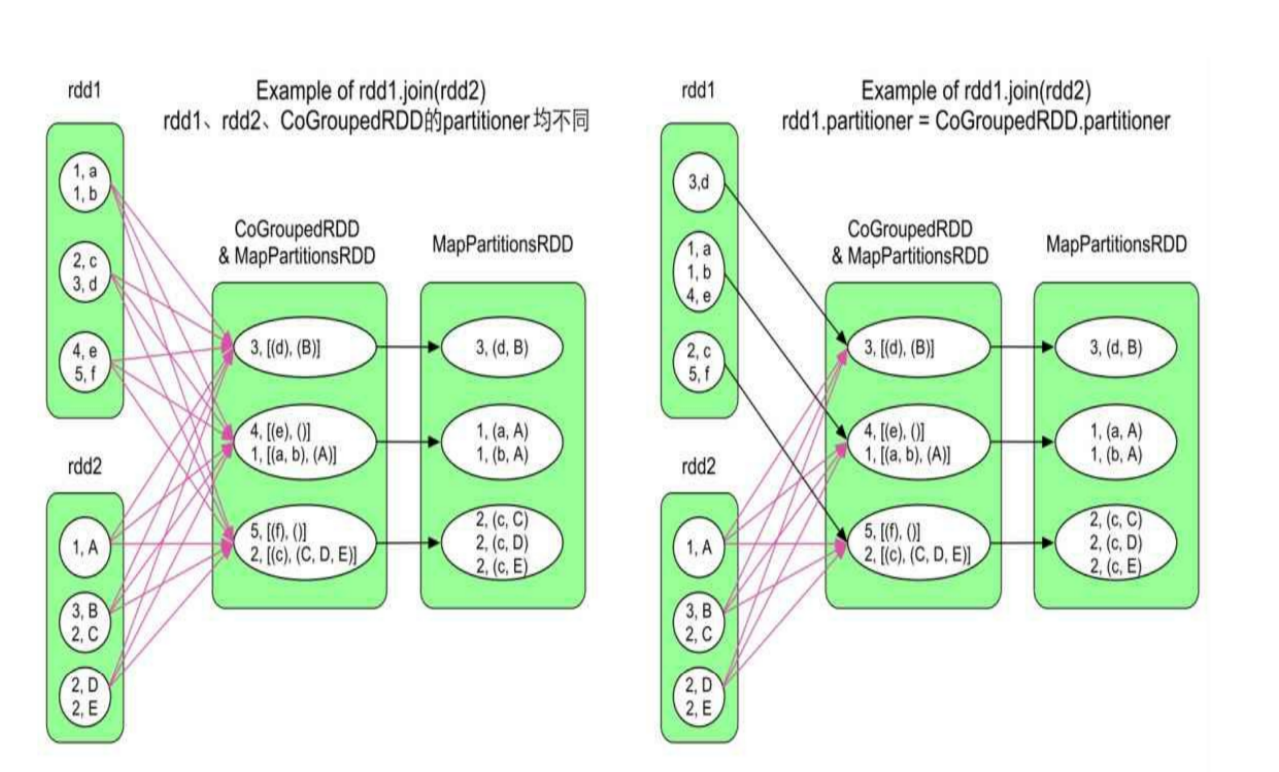
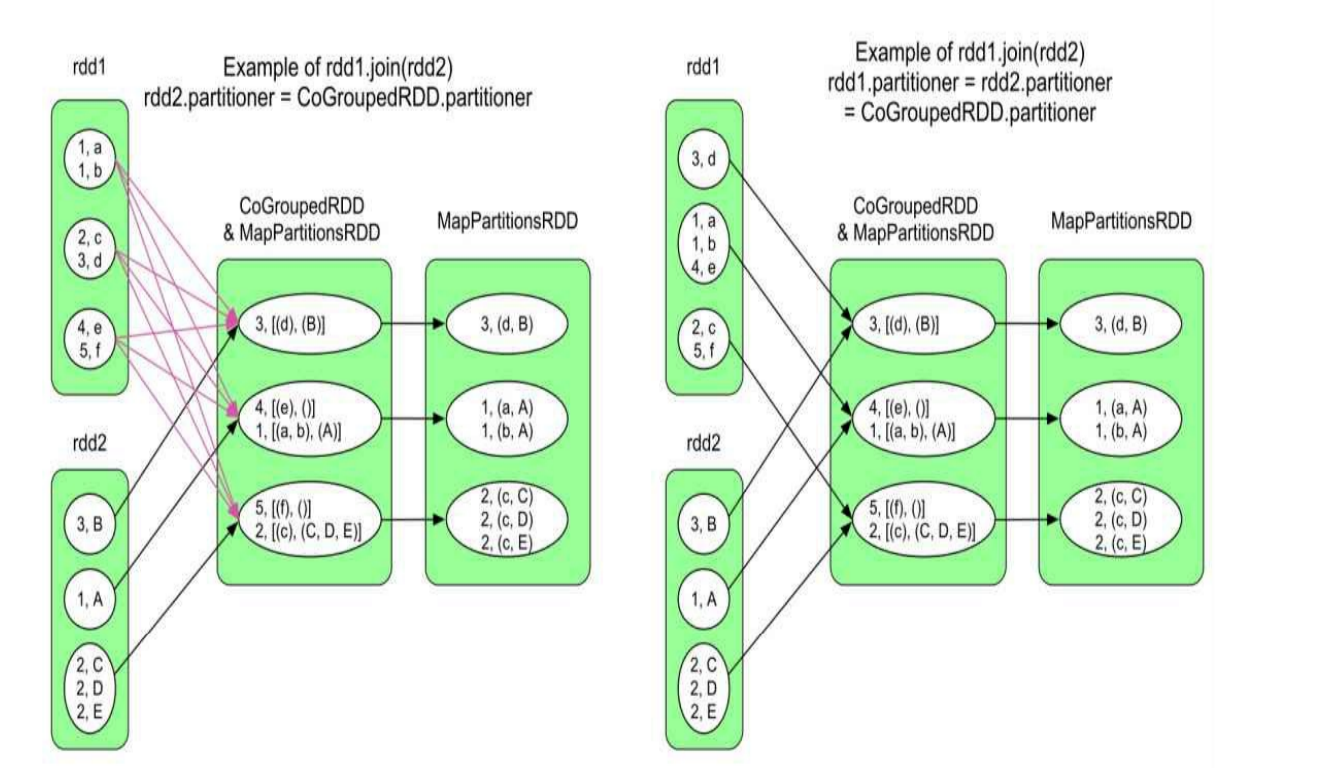 上面这四个图, 产生的 Stage 数目分别是 3, 2, 2, 1
上面这四个图, 产生的 Stage 数目分别是 3, 2, 2, 1
对于第一个图, reduceSide 的 每个 Task 会从6 个子分区拿到初始数据
对于第二个图, 会先计算出 rdd2 之后, CoGroupedRDD 才会计算, CoGroupedRDD的每个分区 有两个数据来源, 一个是 rdd1 他的对口分区, 一个是来自 ShuffleRead, 从 3 个子分区拿到数据
第三个图和第二个图一样的
第四个图只有一个 Stage, 我们把计算目的 RDD 第一个分区的 Task 叫做 Task1, 以此类推, Task1 会从 rdd1 和第一个分区和 rdd2 的第一个分区当作 Task 的初始数据, 直接计算到结尾
SortByKey
SortByKey 只有在一种情况下不是宽依赖, 那就是在父 RDD 也是 Range分区, 而且和子 RDD 的分区数目一样
如果是宽依赖的情况下, MapSide 的 Task 会把自己负责的分区进行 SortByKey 操作, 最后通过采样估计得到一个值, 划分到两个子分区
ReduceSide 的 每个 Task 就负责读取对应的那一批子分区, 再重新排序
还有其他类似各种操作, 都是同理的, 先得看这个算子的具体操作步骤, 然后看实际 Partitioner 的情况看是否需要 shuffle
Action 操作
Action 操作就是向 Spark Driver 提交一个 Job, 这是怎么提供的呢? 来源于前面的 Transformation 的操作
每一个 Transformation 都会产生一个新的 RDD, 但是在实际 Action() 之前, 这些 RDD 都是逻辑上的 RDD, 也就是可以看作, 这些新产生的 RDD 只有一些元数据, 这些数据代表了数据抽象 + 计算逻辑的封装
大概会有这些
- partition 逻辑
- dependency(父 RDD)
- compute 方法(如何从 parent 计算)
- partitioner(如果有)
- iterator 计算逻辑
最后的 rdd.action(), Spark Driver 会构建 DAG, 遇到 shuffle dependency → 切 stage, 每个 stage 生成 task
其中这里有两个需要区分:
1. Logical Plan (逻辑执行计划)
当你写下一连串 Transformation(map -> filter -> join)时,Spark 只是在内存中构建了一棵 RDD 依赖树。
- 本质:记录了数据的来源(Lineage)和计算逻辑。
- 特点:它是静态的,不涉及具体的机器、内存或 CPU 资源。此时数据并没有真正开始流动。
2. Physical Plan (物理执行计划)
当 Action 触发时,DAGScheduler 开始将逻辑图拆解为物理执行步骤:
- Stage 划分:根据 宽依赖 (Shuffle) 切分逻辑链条。每个 Stage 内部都是可以“流水线” (Pipelining) 执行的窄依赖。
- Task 生成:根据 RDD 的 Partition 数量,将 Stage 转化为一个个具体的 Task 实体。
- 任务调度:
TaskScheduler将这些 Task 发送到远程的Executor节点上,绑定具体的 CPU 线程执行。
由于 Spark 是 Scala 写的, 有各种烦人的 OOP 封装, 把上述说的这些玩意又封装成是某些对象的职能, 大概是这样的
Action
↓
SparkContext.runJob
↓
DAGScheduler
↓
构建 RDD DAG(基于 lineage)
↓
按 ShuffleDependency 切分 Stage
↓
每个 Stage 生成 Tasks(按 partition 数)
↓
TaskScheduler 分发到 Executor总之我认为对于这些由’强OOP’语言写的项目中, 更应该关注的是他的一些数据结构和调用流程
聚合
把这些 Task 分发给 Executor 执行之后, 最后 Executor 会把最终的结果, 发送回 Driver 节点, 比如说 reduce 操作, 每个 Executor 分别对自己负责的分区执行 reduce, 然后把最后的计算结果发回 Driver, Driver再把这些数据 reduce
但有的时候, 这些 Executor 传回来的数据太多了, Driver Node 顶不住这些压力, 而且Driver是单点merge,存在效率和内存空间限制问题
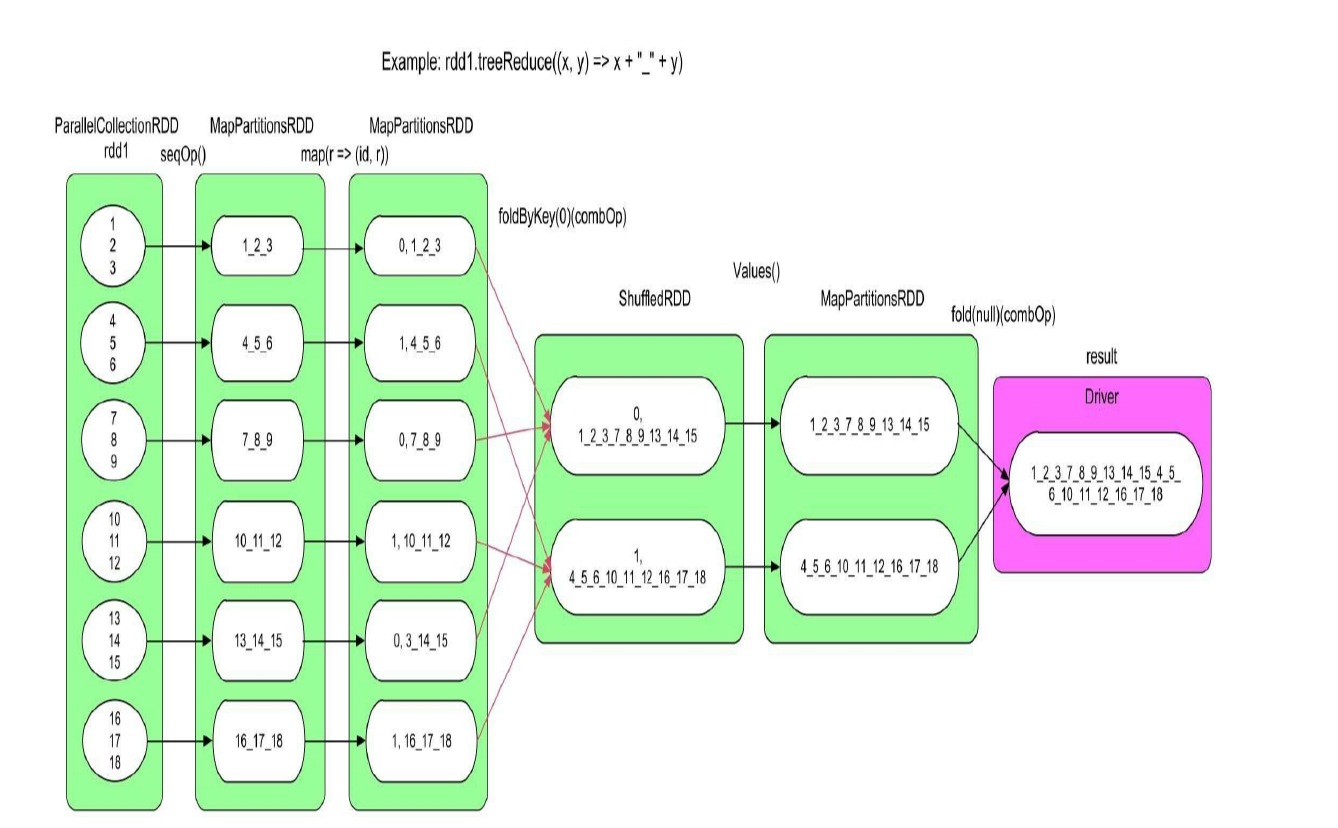
为了解决这个问题,Spark对这些聚合操作进行了优化,提出了treeAggregate()和treeReduce()操作, 把一些原本在 Driver Node 计算的 reduce 操作, 继续在 Executor 中 reduce, 最后的执行流程类似归并操作
持久化
很多时候我们只是需要把结果保存起来, 这个时候调用saveAsTextFile()/ saveAsObjectFile()/ saveAsHadoopFile()/ saveAsSequenceFile() 就行了, 他们的区别就是序列化的方式和持久化的方式
深入 Shuffle
上面提到了 shuffle 是应对分区的变化进行的操作, 会将 Job 划分为两个 Stage, 上一个 Stage 负责把数据提供给下一个 Stage, 下一个 Stage 负责读取这些数据作为自己 Task 的初始数据
Shuffle Write
我们之前只说了整体的逻辑, 即上一个 map side 的 Partition_i 产生 sub_partition_i_0 到 sub_partition_i_n, 然后 reduce side的 Task i 负责读取 sub_partition_0_i 到 sub_partition_N_i
其实对于除了下面说的第一个情况, 一个 map side 的 task, 他只会产生两个文件, 分别是sub_partition_i 和 对应的 index 文件, 而不是每个 sub_partition 都产生一个文件
map side 这一边我们可以从上方看到, 他可以只做分区(groupByKey), 也可以在分区之前执行一个小的 combine 函数, 或者是 sort() 函数
在 map side 端, 每个 Task 会根据 hash 函数, 给每个 record<(K,V)> 计算出一个 partitionID, 最后这个 record<(K,V)> 变成 record<(partitionID, (K,V))>
1. 不需要 map 端聚合(combine)和排序
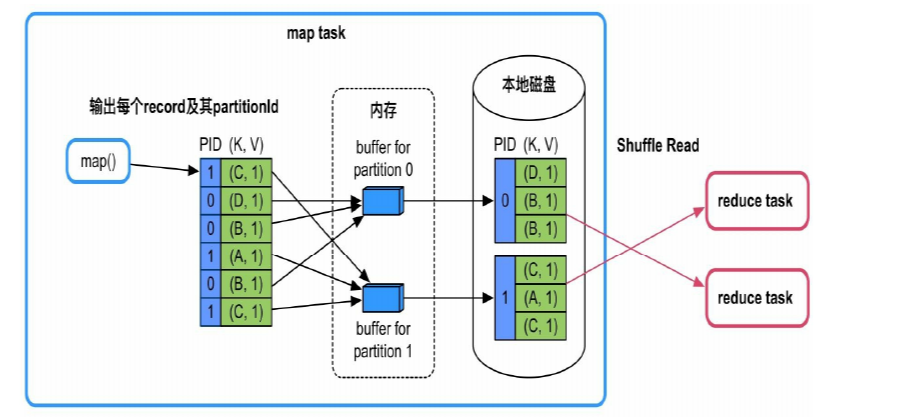
很简单, 把 partition id 算出来之后, 建立 N 个 buffer, 存下这些 records即可, 处理完之后, 每个 buffer 就对应一个 sub partition, 分别持久化到磁盘上即可
该模式的优缺点:优点是速度快,直接将record输出到不同的分区文件中。缺点是资源消耗过高,每个分区都需要一个buffer(大小由spark.Shuffle.file.buffer控制,默认为32KB),且同时需要建立多个分区文件进行溢写。当分区个数太大,如10 000时,每个map task需要约320MB的内存,会造成内存消耗过大,而且每个task需要同时建立和打开10 000个文件,造成资源不足。
因此,该Shuffle方案适合分区个数较少的情况(<=200)。该模式适用的操作类型:map()端不需要聚合(combine)、Key不需要排序且分区个数较少(<=spark.Shuffle.sort.bypassMergeThreshold,默认值为200)。例如,groupByKey(100),partitionBy(100),sortByKey(100)等
2. 不需要 map 端聚合(combine),但需要排序。
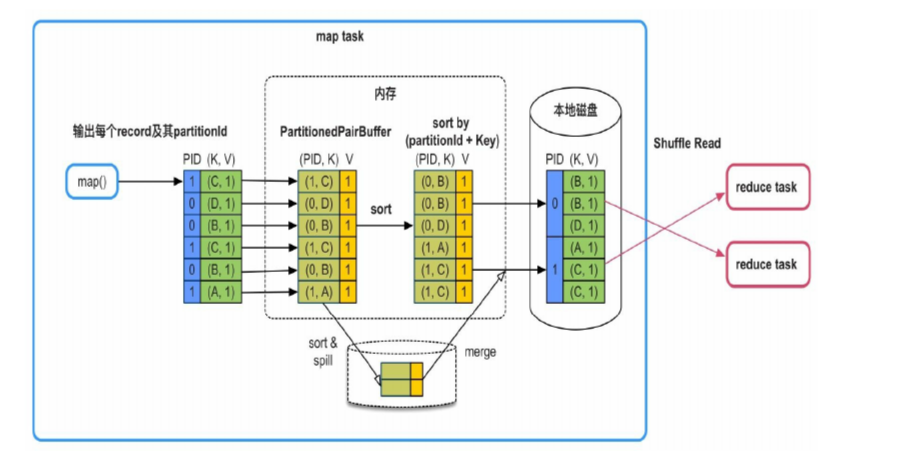 很简单, 这个时候, 把之前的 (PID, (K, V)) 改造成 ((PID, K), V), 再根据 PID + K 进行排序, 便可以做到排序功能, 而且能很好的区分 sub partition
很简单, 这个时候, 把之前的 (PID, (K, V)) 改造成 ((PID, K), V), 再根据 PID + K 进行排序, 便可以做到排序功能, 而且能很好的区分 sub partition
并且他能很好的解决第一个策略中文件数量太多的问题, 只需要将“按PartitionId+Key排序”改为“只按PartitionId排序”,例如,groupByKey(300)、partitionBy(300)、sortByKey(300)
3. 需要map()端聚合(combine),需要或者不需要按Key进行排序
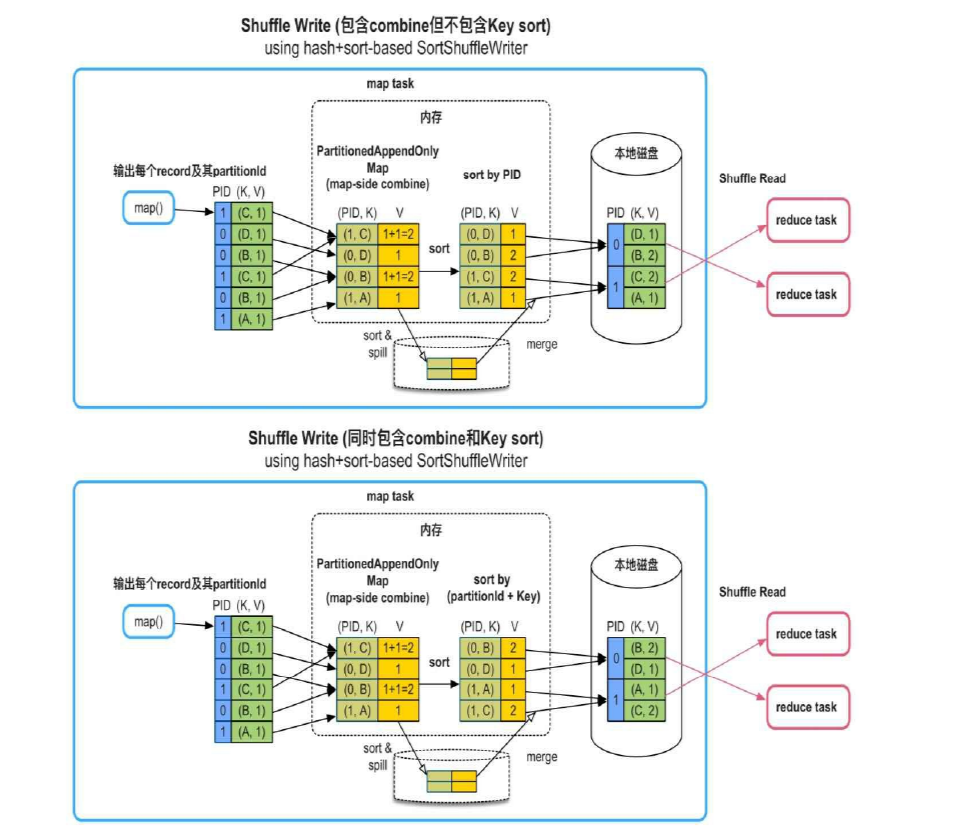 建立一个 Hashmap(Key为PID+K, Value就是V), 然后每次对 hashmap进行 insertOr(combineFunc) 操作, 即先插入 map, 如果已经存在, 就对他的 value 进行 combineFunc 操作, 最后根据时候需要 sort, 进行 PID/ PID + K 排序, 存储文件
建立一个 Hashmap(Key为PID+K, Value就是V), 然后每次对 hashmap进行 insertOr(combineFunc) 操作, 即先插入 map, 如果已经存在, 就对他的 value 进行 combineFunc 操作, 最后根据时候需要 sort, 进行 PID/ PID + K 排序, 存储文件
该Shuffle模式适用的操作:适合map()端聚合(combine)、需要或者不需要按Key进行排序、分区个数无限制的应用,如reduceByKey()、aggregateByKey()等。
Shuffle Read
reduce side 这边同理, 他可以只做分区(groupByKey), 也可以在分区之前执行一个小的 reduce 函数, 或者是 sort() 函数
1. 不需要聚合,不需要按Key进行排序
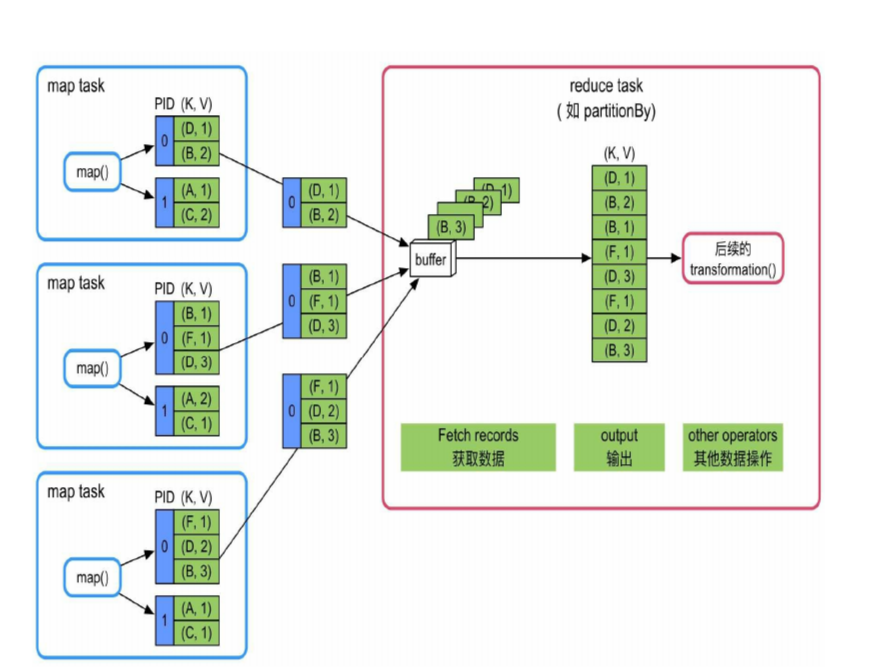 从对应的 sub partitions 获取数据, 合并一下, 就得到了这个分区
从对应的 sub partitions 获取数据, 合并一下, 就得到了这个分区
适合既不需要聚合也不需要排序的应用,如partitionBy()
2. 不需要聚合,需要按Key进行排序
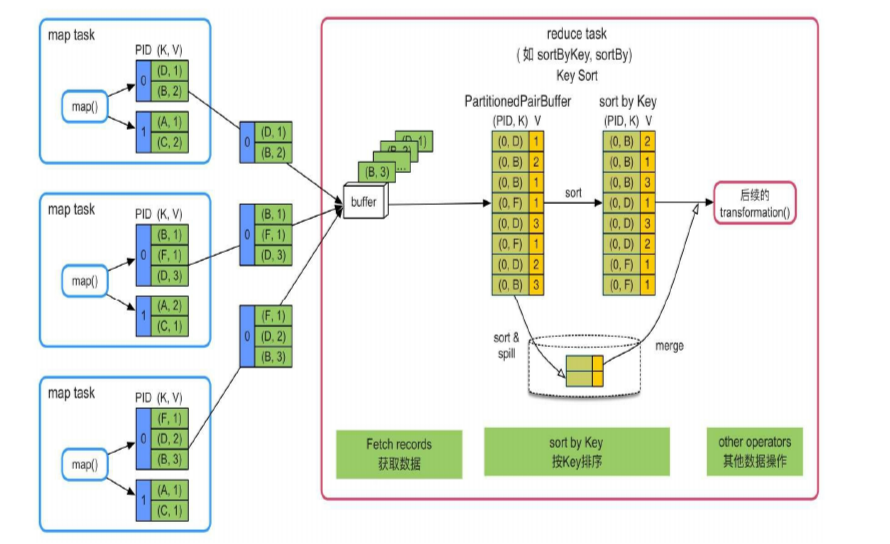 同理, 从对应的 sub partitions 获取数据, 最后在这个大大的buffer中进行排序, 如果 buffer 太大就会暂存到磁盘
同理, 从对应的 sub partitions 获取数据, 最后在这个大大的buffer中进行排序, 如果 buffer 太大就会暂存到磁盘
适合reduce端不需要聚合,但需要按Key进行排序的操作,如sortByKey()、sortBy()等
3. 需要聚合,不需要或需要按Key进行排序
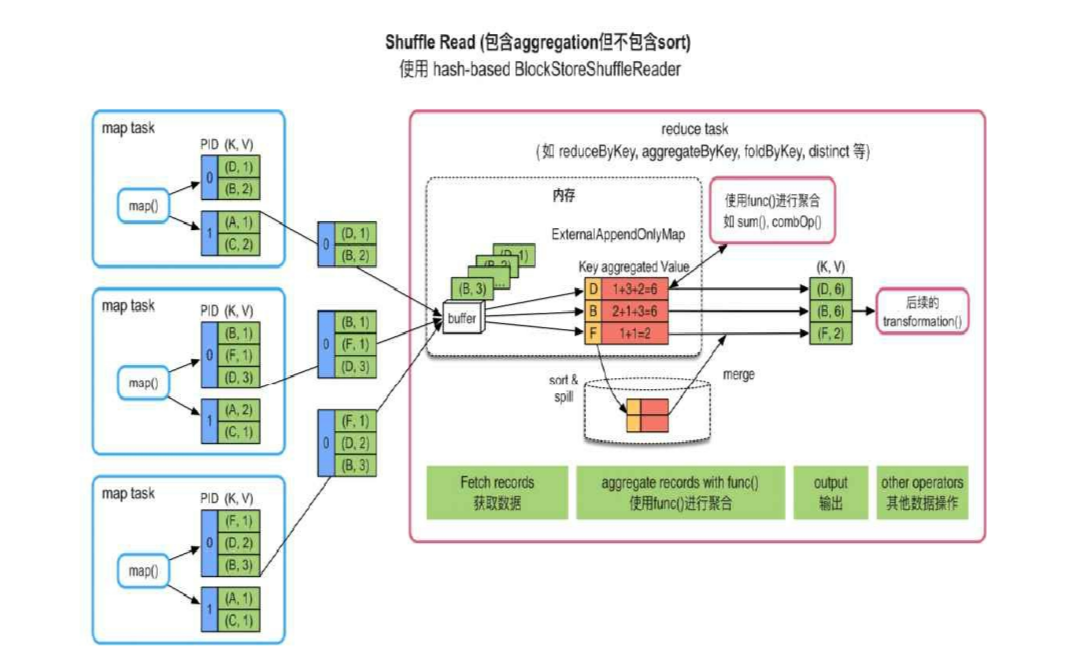
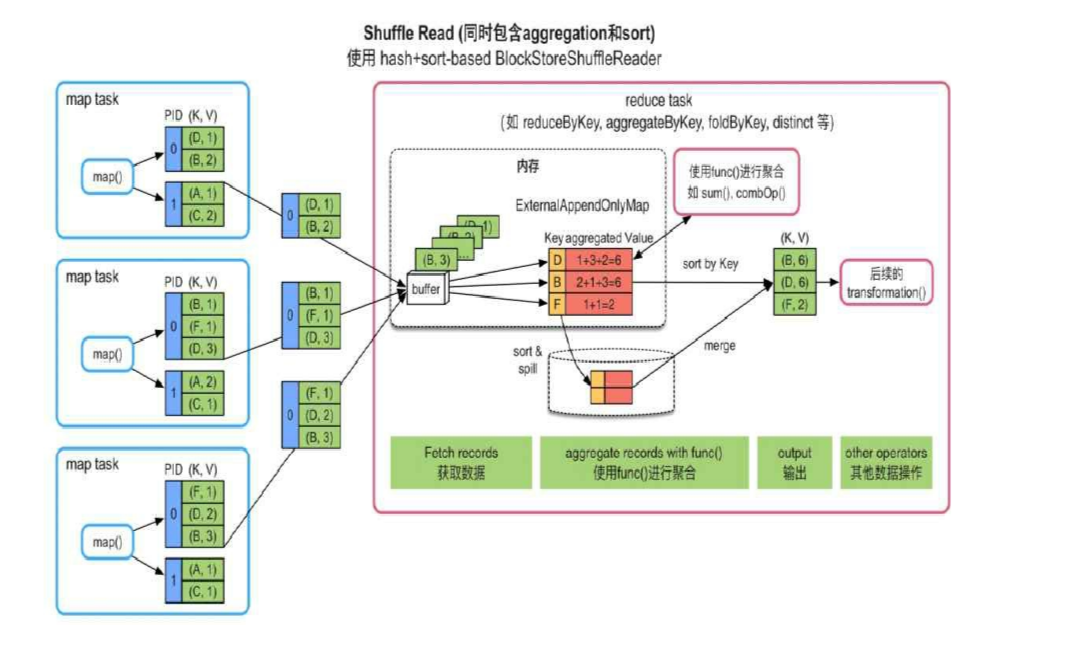 将收集到数据放在一个 Hashmap(Key是K, Value是聚合的数据) 中, 进行 insertOr(reduceFunc) 操作, 如果最后还需要排序, 那么再对这个 hashmap 进行排序即可
将收集到数据放在一个 Hashmap(Key是K, Value是聚合的数据) 中, 进行 insertOr(reduceFunc) 操作, 如果最后还需要排序, 那么再对这个 hashmap 进行排序即可
缓存机制
Spark 的缓存机制通过 persist(level) 这个 rdd 的方法提供, 其中这个 lavel 有很多, 比如是否进行序列化, 是否保存到磁盘, 保存到磁盘后是否多副本, cache() 方法就是 persist(MEMORY_ONLY)的 wrapper
值得注意的时候, persist() 也是惰性求值的, 因为他发生的过程在 action() 提交 job 后, executor 执行的, 在 spark driver 上调用这个方法, 只是给这个 rdd 一个 persist 的标记而已
当一个新的 job 提交的时候, spark driver 上会顺着这个 rdd 向上开始检查(发生在 DAGScheduler 划分 Stage 的时候)
- 逻辑层: 调用
rdd.persist()时,确实只是在 RDD 的元数据里打了一个storageLevel的标签 - 物理层(关键): 当 Action 触发,
DAGScheduler在从后往前划分 Stage 时,会检查 RDD 的getStorageLevel。 - 运行时: 真正的“缓存命中”检查发生在 Executor 端。Task 开始执行时,会先询问本地或远程的
BlockManager:“喂,这个 RDD 的这个 Partition 你缓存了吗?” 没命中才会调用compute()计算
上面说的 getStorageLevel很关键, 他其实就是返回 rdd 的presit 那个 flag, 如果是 None, 那么无事发生, 如果是其他的, 他会调用 getCacheLocs(rdd), 这个方法会去询问 BlockManagerMaster(运行在 Driver 上的一个全局管理器):“这个 RDD 的第 N 个 Partition,在集群的哪个 Executor 的内存/磁盘里?”
- Case A (第一次运行):
BlockManagerMaster回复“我没见过这玩意”。于是 Scheduler 正常划分 Stage,下发 Task, 并且 executor 负责执行 persist, 并把这个消息同步给 driver - Case B (非第一次运行):如果之前已经计算过且成功 persist,
BlockManagerMaster会返回具体的BlockId和位置。此时,Scheduler 会发现这个 RDD 已经是“现成的”了,从而截断依赖链,不再向上寻找父 RDD, Task 启动后的第一件事不是compute(), 而是先看有没有缓存
值得注意的是, 只有在 action() 之后, rdd 才会真的被缓存, 也就是说得注意 job 的提交时期, 避免没用上 cache
错误处理
对于Spark等大数据处理框架,错误容忍需要考虑以下两方面的问题
- 作业(job)执行失败问题:Spark在执行job时,可能因为软硬件环境、配置、数据等因素的影响,导致job执行失败。具体表现有task长时间无响应、内存溢出、I/O异常、数据丢失等。问题原因多种多样,既包括硬件问题,如节点宕机、网络阻塞、磁盘损坏等;也包括软件问题,如内存资源分配不足、partition配置过少导致task处理的数据规模太大、partition划分不当引起的数据倾斜,以及用户和系统Bug等
- 数据丢失问题:Spark job在执行过程中,会读取输入数据、生成中间数据、输出结果。由于软硬件故障,如节点宕机,会导致某些输入/输出或中间数据丢失. 例如,task的输入数据既可以来自分布式文件系统,也可以通过Shuffle获取,如果在Shuffle机制中数据丢失怎么办?如果对一些重要数据进行缓存后,缓存数据由于节点宕机等故障丢失怎么办?另外,一个应用经常包含多个job,当前job的输出数据是下一个job的输入数据,那么当前job的输出数据丢失怎么办? 简而言之, 第一个问题是, 当前这个环境跑不下去了, 第二个问题是, 需要的数据丢失了
对于第一类问题, Spark 只能解决由于执行环境改变而引发的应用执行失败, 比如说节点宕机、内存竞争、I/O异常导致的任务执行失败, 即是可以通过重新计算来尝试修复的错误
对于第二类问题, Spark采用的是数据检查点持久化方案, checkpoint 机制
重新计算机制: 基于 RDD Lineage
Spark 每个 RDD 都会记录它的 Lineage(血统/依赖关系)
比如说, 当一个 Worker 发生了宕机事件, 他上面运行的 Task 得到的 RDD 分区肯定都拿不到了, 这个时候 Spark 会去看当前 Stage 最后的 RDD 的依赖链, 并顺着这个依赖连重新在一个 Worker 上计算
那最终要从哪里开始计算呢? 这取决于离当前 Task 最近的数据在哪
- 如果这个 Task 最初的数据来源是外部的文件数据, 重新读取即可
- 如果这个 Task 最初的数据来源于 Shuffle Read, 不必担心, Spark采用了“延时删除策略”,即将上游stage的Shuffle Write的结果写入本地磁盘,只有在当前job完成后,才删除Shuffle Write写入磁盘的数据. 这样 Task 的重新计算只用重新 Shuffle Read 即可
- 如果顺着依赖链往上追溯发现有缓存数据存在, 那么从这个缓存数据对应的 RDD 开始就行
Checkpoint 机制:斩断依赖链
上面可以看到, 如果说一个 Task 的计算链条太长了, 中间也没有 cache 过, 那么岂不是要重新计算很久? 或者这个 Task 是在多个job串联执行的情况下, 那么这个问题就更显著了, 因为每执行完一个job后,Spark会将该 job 中上游 stage 的 Shuffle Write 数据都删除
Checkpoint 通过物理持久化来截断依赖, 解决这个问题
运作流程
- 标记:用户调用
rdd.checkpoint()。此时什么都不会发生,Spark 只是打个标记 - 执行 Job:必须触发一个 Action 操作(如
count),Job 完成后,Spark 会额外启动一个专门的 Checkpoint Job - 落地存储:将 RDD 的数据写入可靠的分布式文件系统
- 切断联系:一旦数据写完,该 RDD 之前的所有 Lineage 全部删除。该 RDD 的状态被改为
CheckpointRDD,后续计算如果报错,直接从 分布式文件系统 读,不再回溯
注意, 他和 persist 一样, 是 action 之后才会真正的持久化的, 需要注意调用的时机
Checkpoint vs Persist (cache)
你可能觉得这个不就是 persist 吗, 实则不然, 他还修改了 RDD 的 Lineage 数据, 而且 checkpoint 认为这个持久化是可靠的
还有一个区别是, 数据缓存速度较快,对job的执行时间,影响较小,因此可以在job运行时进行缓存。而checkpoint写入速度慢, 为了减少对当前job的时延影响,会额外启动专门的job进行持久化
Spark 建议用户在 checkpoint RDD 的同时对其进行缓存, 这样重试的时候, 还能从更快的恢复数据
内存管理
1. For Task: Framework memory
内存主要分为两块地盘:
- Storage Memory(存储内存):用于
cache、persist和broadcast变量。 - Execution Memory(执行内存):用于
Shuffle、Join、Sort、Aggregation过程中的中间数据, 以及用户的代码 - 用户代码空间: 比如说用户的 flatMapFunc 里面出现了数组啥的
在这3个分区中,数据缓存空间和框架执行空间组成(共享)了一个大的空间,称为Framework memory。Framework memory 大小固定,且为数据缓存空间和框架执行空间设置了初始比例,但这个比例可以在应用执行过程中动态调整,如框架执行空间不足时可以借用数据存储空间来“Shuffle”中间数据
同时,两者之间比例也有上下界,使得一方不能完全“侵占”另一方的空间,从而避免因为某一方空间占满导致后续的数据缓存操作或Shuffle操作无法执行, 而且存储内存不能强制抢占正在使用的执行内存, 为了防止 Shuffle 算一半崩溃
对于用户代码空间,Spark将其设定为固定大小,原因是难以在运行时获取用户代码的真实内存消耗, 也就难以动态设定用户代码空间的比例
另外,当框架执行空间不足时,会将Shuffle数据spill到磁盘上;当数据缓存空间不足时,Spark会进行缓存替换、移除缓存数据等操作
堆内和堆外
此外, Storage Memory 和 Execution Memory 还都有堆内和堆外的区分
- 堆内内存
- 实现:受 JVM 管理,本质上是大量的 Java 对象(或者序列化后的
byte[]) - 痛点:GC 停顿(Stop-the-World)。当你在堆内缓存了数亿个小对象时,JVM 扫描对象引用的开销会拖垮整个 Job
- 布局:由
spark.executor.memory指定总额
- 实现:受 JVM 管理,本质上是大量的 Java 对象(或者序列化后的
- 堆外内存 (Off-Heap / Tungsten)
- 实现:通过
sun.misc.Unsafe直接调用操作系统的malloc申请内存 - 优点:完全脱离 GC 掌控。数据以二进制(Binary Row)形式存储,内存布局极其紧凑
- 布局:由
spark.memory.offHeap.size指定
- 实现:通过
2. For Executor
一个 Spark Executor 进程占用的总内存(由 spark.executor.memory 指定)主要分为三大部分:
- Reserved Memory(预留内存):硬编码在源码里的 300MB。它是 Spark 预留给系统内部运行(如储存解析后的类、对象等)的“保命钱”,不参与任何动态分配
- User Memory(用户内存):占比约为 25%(由
1 - spark.memory.fraction决定)。用于存放用户自定义的数据结构、Spark 内部元数据,或者是没有被 Spark 框架管控的 RDD 转换操作。如果你的代码里new了一堆大对象,都在这里 - Spark Memory(框架管理内存):占比约为 75%(由
spark.memory.fraction决定)。这是核心地盘,由UnifiedMemoryManager统一管理
BlockManager
在 Spark 的分布式架构里,每个 Executor 都有一个 BlockManager。你可以把它看作是一个本地的对象存储代理。它不光管内存,还管磁盘、管跨节点的数据传输, 他有这些核心组件
- DiskStore:负责把数据写到本地磁盘。
- MemoryStore:负责管理内存中的数据对象。
- BlockTransferService:负责从远程节点拉取(fetch)数据(比如 Shuffle Read)。
- BlockManagerMaster:这是运行在 Driver 上的大脑。每个 Executor 的 BlockManager 都要向它汇报:“我这里有哪些 Block,在哪台机器上”
MemoryStore
我们要关注的主要就是 MemoryStore , 他是专门负责处理内存中数据存放、读取和驱逐**的组件, 它不关心数据是在 Shuffle 还是在 Cache,它只关心:这块数据我能不能塞进当前的内存池里?
MemoryStore 并不是直接管一堆 byte[],它管理的是 MemoryEntry. 根据数据的形态,MemoryEntry 分为两种
- DeserializedMemoryEntry: 存的是原始的 Java 对象(Object)。读取最快,但极其占内存,且 GC 压力巨大
- SerializedMemoryEntry: 存的是序列化后的
ByteBuffer。节省空间,对 GC 友好,但读取时需要 CPU 进行反序列化
他会使用类似 Hashmap 来存储一个数据, 其中 Key 是 BlockID, 对于 DeserializedMemoryEntry, Value 是指向 Java 对象的引用, 对于SerializedMemoryEntry, Value 是指针, 指向堆外内存
BlockId 是用于标志一个数据的 Tag, 比如说 Task1 要 cache() 他的分区数据, 这个Partition 的 BlockId 可能就是 (rddId, partitionId), 对于 Task 最终的计算出来的 Partition, BlockId 可能就是 (taskId)
存入流程:非对称的“试探”机制
这是 MemoryStore 最精妙的地方。为了防止 OOM,它在存入数据前会进行预估和申请:
- 申请内存(Acquire Storage Memory): 当一个 Task 要往
MemoryStore放数据时,它必须先向MemoryManager申请足够的空间。 - 展开(Unroll)过程: 这是最容易出问题的一步。如果你要把一个
Iterator存入内存,Spark 并不知道这个 Iterator 有多大。MemoryStore会逐渐迭代这个 Iterator,每读取一部分数据,就向MemoryManager申请一次内存。- 如果申请失败(内存满了),这个过程就会中断。这就是所谓的 Unroll Memory(展开内存)
- 落地(Finalize): 如果整个 Iterator 成功“展开”且内存足够,它才会正式转变为
MemoryEntry留在内存里。
驱逐策略:LRU 与 内存抢占
当 MemoryStore 发现新数据放不下时,它会启动“清理”机制:
- LRU (Least Recently Used): 它维护一个
LinkedHashMap来记录 Block 的访问顺序。最久没用的 Block 会被剔除。 - 去向(Spill): 被剔除的 Block 命数取决于你的
StorageLevel:- 如果是
MEMORY_ONLY:直接抹除。下次要用?通过 Lineage 重算。 - 如果是
MEMORY_AND_DISK:调用DiskStore将其写回磁盘。
- 如果是
DataFrame 的优化
1. Catalyst 优化器:从 SQL 到 RDD 的 GigaChad 🗿
Catalyst 是一个基于 Scala 函数式编程 构建的树形转换框架。它的核心逻辑只有一句话:给定一棵树(逻辑计划),应用一套规则(Rules),输出一棵更优的新树。
1. Logic DAG 的优化
Catalyst 会用 它会利用关系代数的等价变换,把低效的查询变高效
A. 谓词下推
- 动作:将
filter操作尽可能地移向数据源(数据读取端), 即提前 filter 操作 - 原理:如果你写
df.join(df2).filter("id > 100"),Catalyst 会自动拆解 filter,把它推到 Join 之前。 - 软件工程意义:减少了网络传输(Shuffle)的数据量。而且还能少算很多计算
B. 列剪枝
- 动作:只读取
select中声明的列 - 原理:如果你有一张 1000 个字段的宽表,但只要
name,Catalyst 会在物理扫描阶段就告诉数据源:“剩下的 999 列别发给我”, 这是因为 DataFrame 有 Schema 的概念才能做到的, 如果是 RDD 那么只能一口气发过来
C. 常量折叠 && 简化逻辑
- 动作:预计算。
- 例子:
filter(age > 10 + 5)会被转换成filter(age > 15);where(1 == 1)会被直接删掉。
物理计划的优化
到了物理计划阶段, Catalyst会根据代价模型选择执行路径, 代价模型就是预估这些操作需要花费的代价, 选择一些其他的手段来优化它
Example: Join 策略的选择 这是最容易拖慢 Job 的地方,Catalyst 会权衡以下几种方案:
- BroadcastHashJoin: 如果一张表很小(默认 < 10MB),它会把小表广播到所有节点。优点:没有 Shuffle
- ShuffleHashJoin:两张大表 Join 的标准做法。过程:先对两个表按照 Join Key 进行 Hash 分区, 相同的 Key 会被分到同一个 Executor, Executor 选出一张相对较小的表(内表),在内存里构建一个
ExternalAppendOnlyUnsafeRowMap, 流式读取另一张大表(外表)的每一行,去哈希表里“查表”匹配 - SortMergeJoin:同样先对两个表按照 Join Key 进行 Hash 分区, 相同的 Key 会被分到同一个 Executor, 在每个 Executor 内部,对两张表的数据分别按 Key 进行排序, 既然两边都排好序了,Spark 只需要用两个指针(Pointer)分别指向两张表的开头,像拉拉链一样对齐即可 Catalyst 会根据表的统计信息(行数、大小)自动选。
2. Tungsten 的全阶段代码生成 🗿
这是 Spark 2.x 之后最硬核的优化。传统的 RDD 处理是“火山模型(Volcano Model)”,每一行数据都要经过一层层算子函数的调用,虚函数调用开销极大,且对 CPU 缓存极不友好
在 RDD 时代,每处理一行数据,都要经历一次 iterator.next()。如果你的逻辑是 Filter -> Map -> Aggregate,那每一条 Record 都要在三个对象、三个迭代器之间反复横跳。这在 CPU 层面意味着大量的**虚函数调用(Virtual Function Call)**和内存寻址,完全打碎了 CPU 的流水线(Pipeline)和分支预测。
Tungsten 会在物理执行前,动态地生成一段 Java 字节码。它把你的整个 Filter -> Project -> Aggregate 链路打碎,拼成一个巨大的 for 循环, 也就是每一行数据都是直接计算得到最后的 Record
最后生成的代码看起来就像你自己手写的一个高性能循环, 你在 Spark UI 里看 DAG,如果算子上面带个 (*),比如 *(1) Filter,就说明它被 CodeGen 优化了
3. 内存层面的 Row 格式
前文提到了, DeserializedMemoryEntry 他是直接的 Java 对象, Dataframe 彻底抛弃了它
在 Dataframe 中, 这些 Records 数据都是以 UnsafeRow 格式存储的。它是一个连续的字节数组
布局:[Null 位图] + [固定长度值区] + [变长数据偏移区]。
4. AQE 动态优化
AQE 让 Spark 在跑完一个 Stage 后,根据实际统计信息重新调整后面的计划
- 动态合并分区 (Coalescing Post-Shuffle Partitions):如果你 Shuffle 后发现每个分区只有几 KB,AQE 会自动把它们合并成一个大分区,避免启动几千个 Task 跑几毫秒的尴尬
- 动态 Join 策略切换:原本预估是大表 Join,结果 Filter 完发现一边只有 5MB,AQE 直接把
SortMergeJoin降级为BroadcastHashJoin - 处理数据倾斜 (Skew Join Optimization):如果发现某个 Key 的数据量是别人的 100 倍,AQE 会自动把这个大 Partition 拆开,分给多个 Task 跑,防止那个“倒霉蛋”Task 拖慢整个 Job
也就是说他通过执行时候获得的信息, 动态更改物理执行计划
Comments
Loading comments...